
이번에는 저번 논문리뷰인 saliency map을 조금 더 발전시킨, SmoothGrad라는 기법에 대해 알아보려고 한다.
https://arxiv.org/abs/1706.03825
SmoothGrad: removing noise by adding noise
Explaining the output of a deep network remains a challenge. In the case of an image classifier, one type of explanation is to identify pixels that strongly influence the final decision. A starting point for this strategy is the gradient of the class score
arxiv.org
핵심 아이디어를 간단하게 말하면,

바로 이것이다. image에 noise를 더한 후 비슷한 여러 이미지를 만든다. 그 후 이러한 이미지들에서 나온 saliency map (sensitivity map)을 평균내서 각 이미지에 대한 최종 sailency map을 출력한다.
또한,

training time에서 noise를 더하는 것이 saliency map에 de-noising effect를 가져온다는 것을 발견하였다.
Gradients as Sensitivity Maps
우선은, 이전에 다루었던 sailency map에서 시작한다.
2025.03.26 - [Explainable AI] - [논문리뷰] Saliency Map
[논문리뷰] Saliency Map
이번에는 Saliency Map Visualisation을 통해서 시각화를 하는 방법을 알아볼 것이다."Deep Inside Convolutional Networks: Visualizing Image Classification Models and Saliency Maps" 라는 논문이다. 논문 원문은 https://arxiv.org/
jaehoonstudy.tistory.com
Saliency Map에 대해서는 위 게시물에 있지만, 논문 원문에 수록된 대로 간단히 다뤄보면,

class score에 대한 이미지의 gradient를 Mc(x), 즉 saliency map이라고 하는 것이다.
이를 이미지로 보면,

이런 식의 saliency map이 나오게 된다.
여기서 저자들의 Figure 1에 대한 설명이 재미있는데, 논문의 motivation이 여기서 나온다. 이러한 raw gradient들은 굉장히 noisy하며, saliency map이 나오더라도 뭔가 의미를 가지는 것 같지 않아보인다.
이런 noise가 나오는 데에 이유는,
Non-smoothness & Fluctuations in gradients
저자들의 설명을 보면, gradient들이 smooth할 이유가 애초에 없다고 말한다. ReLU가 piece-wise linear하기 때문에 derivative들이 region에 따라 급격하게 변화할 수 있는 것이다. 또한 다루고 있는 Neural Network가 ReLU 기반이기 때문에 "will not even be continuously differentiable" 이라고 설명한다.
또한 저자들은 gradient가 굉장히 민감하고 fluctuation이 심하다는 점을 지적한다. 다음의 논문 이미지를 보자.

빨간색, 초록색, 파란색 선은 각각 하나의 pixel에 대한 RGB gradient이다 (우리의 사진은 RGB의 3 channel이니까).
원래 이미지를 baseline 이미지로 놓고(x), 원래 이미지에 0~1 사이의 값을 갖는 t를 엡실론과 함께 더해주었을 때의 gradient 변화를 표로 보여주고 있다. 엡실론 * t 의 결과가 매우 작은 값임에도 불구하고, 조금의 변화만 가해져도 gradient들이 급격하게 fluctuate 하는 모습을 볼 수 있다.
SmoothGrad의 핵심 Method
결국 핵심은 원본 이미지에 Gaussian noise를 첨가한 여러 장의 이미지들에 대한 sailency map을 다 구한 다음, 이를 평균내버리는 것이다. 이는 논문에서 수식으로도 확인 가능하다.

Mc()가 saliency map을 구하는 함수이고, 이 함수 안에 들어가 있는 친구들이 원본 이미지 x에다가 Gaussian noise를 더해준 애들인 상태이다. 이를 앞에 summation과 1/n으로 평균내주는 과정을 볼 수 있다.
적정 noise와 n의 개수
위의 method 부분에서 noise를 첨가하고, 여러 장의 perturbation된 이미지를 평균내주는 과정이 있었다. 그러면 적절한 noise 정도는 얼마나 되며, 이미지는 몇 장까지 뽑아서 평균내는 것이 적절한가? 라는 의문점이 들 수 있다.

위의 그림은 noise 수준을 변화시켜가며 saliency map이 어떻게 나오는지를 실험한 결과 figure이다. 저자들은 10~20%의 noise가 saliency map의 sharpness와 원본 이미지의 structure을 가장 잘 균형잡으며 보존한다고 결론내렸다.
또한, 적정 숫자 n에 대해서는

n이 증가하면 할 수록 결과물이 좋아지고 gradient가 smooth하게 되긴 하나, n > 50 이 되면 큰 차이가 없음을 발견하였다.
Some more about Gradients
저자들은 gradient에 대해서 2가지 점을 추가로 짚고 넘어가는데,
1. gradient의 절댓값을 활용하는 방식
2. outlier gradient를 제외하는 방식
이 그것들이다.
먼저 1번에 대해서는, 데이터셋에 따라 그 경우가 달라진다. MNIST와 같은 흑백 데이터셋은 gradient가 positive할 수록 속한 class에 대한 positive signal을 의미하지만, ImageNet과 같은 데이터셋에서는 gradient의 절댓값을 취하는 것이 좀 더 clear한 saliency map을 출력한다고 서술한다.
Some more Images

실제 구현
다음은 ipynb로 간단한 구현을 해본 것이다.
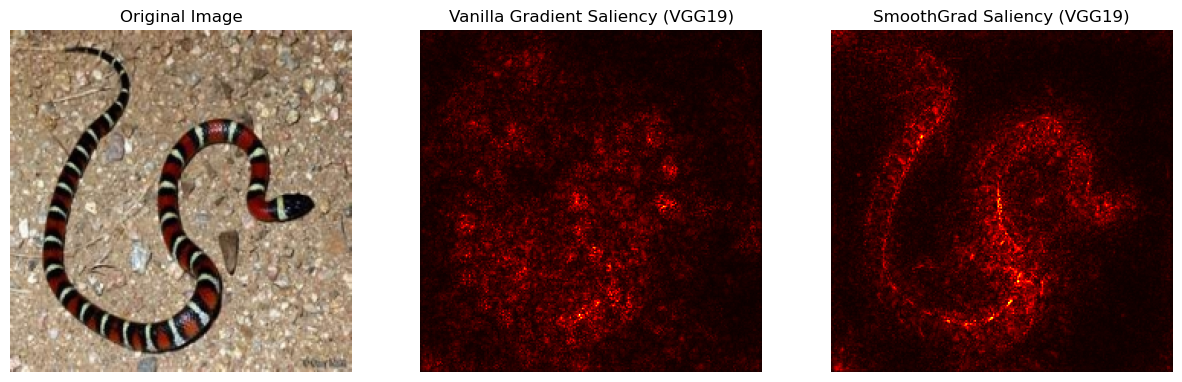
ImageNet으로 VGG19를 훈련시킨 pretrained 모델을 가져왔으며, ImageNet dataset이기 때문에 abs(gradient), 즉 gradient의 절댓값을 사용하였다. 왼쪽은 vanilla gradient, smoothed 되기 전 raw gradient의 saliency map이며, 오른쪽은 SmoothGrad를 활용한 saliency map이다. 훨씬 더 선명한 모습을 볼 수 있다.
Full code: https://github.com/ShinyJay2/Explainable-AI/tree/main/SmoothGrad
Explainable-AI/SmoothGrad at main · ShinyJay2/Explainable-AI
Implementations of XAI. Contribute to ShinyJay2/Explainable-AI development by creating an account on GitHub.
github.com