
이전에 다뤘던 Activation Maximization, Saliency Map 등은 각 hidden layer의 feature map을 시각화하여 설명가능한 AI를 구현하는 방식이다.
하지만 이는 깊은 layer일수록 해석이 힘들고, 사람마다 해석이 다를 수 있으며, 약간 애매모하다는 단점이 존재한다.
이번에 다룰 LRP는 HeatMap 방식의 설명을 제공하는 방법론 중 대표적인 방법론이며, 모델의 결과를 역추적해서 입력 이미지에 HeatMap을 생성하는 방식이다.
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0130140
On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation
Understanding and interpreting classification decisions of automated image classification systems is of high value in many applications, as it allows to verify the reasoning of the system and provides additional information to the human expert. Although ma
journals.plos.org
저자 목록을 보면, Klaus-Robert Müller 교수님이 있는데, 우리 학과 교수님이고, 학교에서 초청 강의도 들은 적이 있어서 굉장히 반가웠다. 이분께서 Unsupervised Learning에서도 일어나는 Clever Hans 문제에 대해서 나온 매우 최신 nature 논문이 있는데, 기회가 되면 리뷰해보고 싶다.
LRP framework as a General Concept
저자들의 LRP를 위한 framework는 크게 두 단계로 나눌 수 있다.
1. Pixel-wise Decomposition
2. Layer-wise Relevance Propagation
먼저, 사진을 하나 보자.
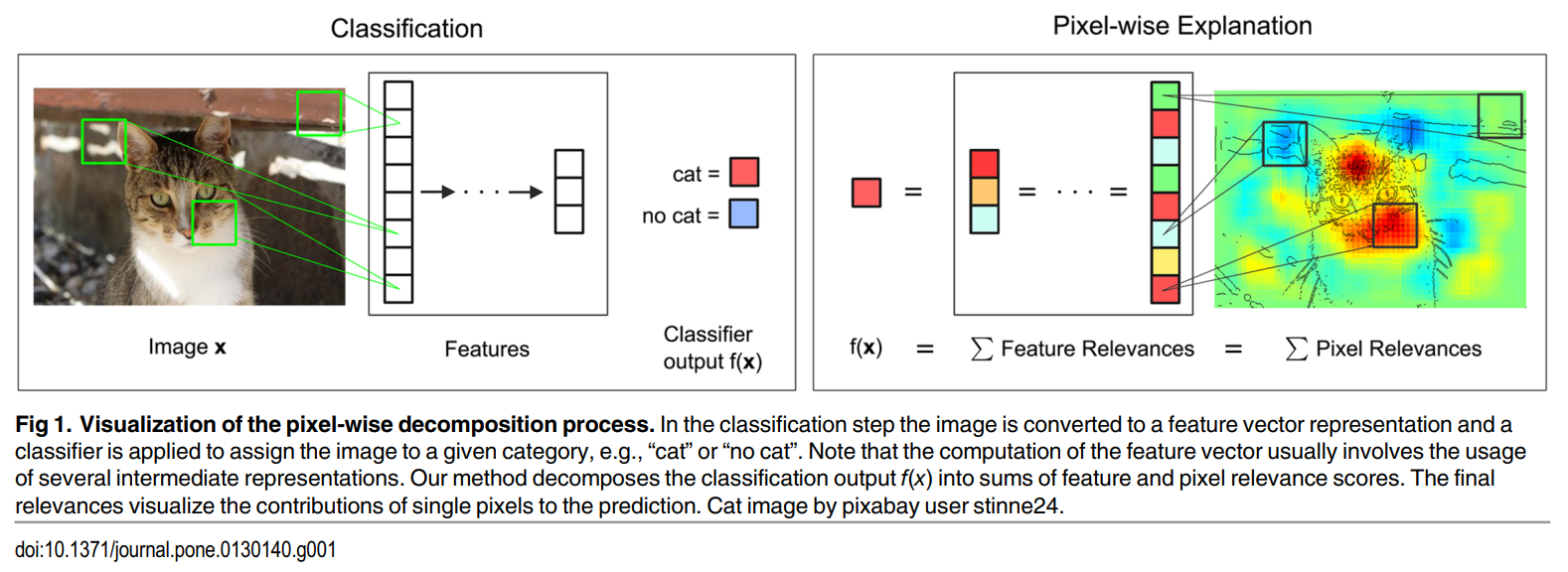
왼쪽의 classification 과정을 보면, CNN의 전형적인 작동과정이다. 이미지를 filter로 쭉 돌리고 이를 feature vector로 바꾼 후에, classifier 층을 통과하고 class output인 f(x)가 나온다.
오른쪽이 저자들의 핵심 아이디어이다.
저자들의 핵심 아이디어는, 이 classifier output인 f(x)를 각 feature들의 relevance score의 합으로 표현할 수 있다는 것이고, 각 feature들의 relevance score의 합은 각 pixel들의 relevance score의 합으로 다시 표현할 수 있다는 것이다.
쉽게 말해 output에 대한 기여도를 쪼개고 또 쪼개면 pixel 단위의 classifier output에 대한 기여도를 얻을 수 있다는 것이다.
그러면 이 "쪼개기"를 대체 어떻게 수행하냐?
그게 바로 LRP, Layer-wise Relevance Propagation 이다.

R_d는 여기서 pixel x_d에 대한 Relevance들이다. 결국 classifier output인 f(x)를 픽셀들이 R_d들의 합으로 근사할 거다! 라는 뜻이다.
* Important Constraint
Pixel-wise Decomposition의 전체적인 소개 부분에서,
저자들은 classification을 할 때 중요한 constraint를 다룬다. 바로 다음과 같은 부분인데,
"The important constraint specific to classification consists in finding the differential contribution relative to the state of maximal uncertainty with respect to classification which is then represented by the set of root points f(x0) = 0."
영어가 읽기 싫다면 볼드체 부분만 이어 붙여서 읽으면 된다.
저자들은 각 pixel의 contribution을 측정할 때, state of maximum uncertainty에 대해서 contribution을 측정한다. 다시 말해, 가장 불확실한 상태를 기준으로 classification에 얼마나 contribution 했는가를 측정하겠다는 뜻이다.

예를 들어, 고양이가 주어진 이미지 x_0 안에 있는지를 알아보고 싶다고 가정해보자.
classifier output이 양수이면 고양이가 사진 속에 있다.
classifier output이 음수이면 고양이가 사진 속에 없다.
라고 측정한다. 하지만 이때, classifier가 가장 불확실하고, 정보가 없는 상태는 f(x_0)이 딱 0인 상태이다.
이게 기준이 되는 것이다.
저자들이 하고자 하는 것은,
classifier의 output을, 각 pixel들에 "기여도 점수"를 각각 매겨서 설명하고자 하는 것이다.
그러면 baseline 이미지, 즉 "기여도 점수"가 없는 상태는 어떤 상태일까?
Black image도 아니고, Random image도 아니고, Empty image도 아니다. 바로 f(x) = 0인 decision boundary가 그 baseline 기준이라는 것이다.
Layer-wise Relevance Propagation
저자들은 LRP를 contraints의 집합으로 정의한다. 다시 말해, 저자들이 적어놓은 제약조건들을 모두 만족한다면, 어떤 것이던 LRP라고 부를 수 있는 것이다.
가장 대표적인 조건은, Relevance Conservation Condition이다.
다시 말해, 각 layer의 relevance의 총합은 다음 layer에 그대로 전달, 다음 layer의 relevance의 총합도 이전꺼와 동일해야 한다는 뜻이다.
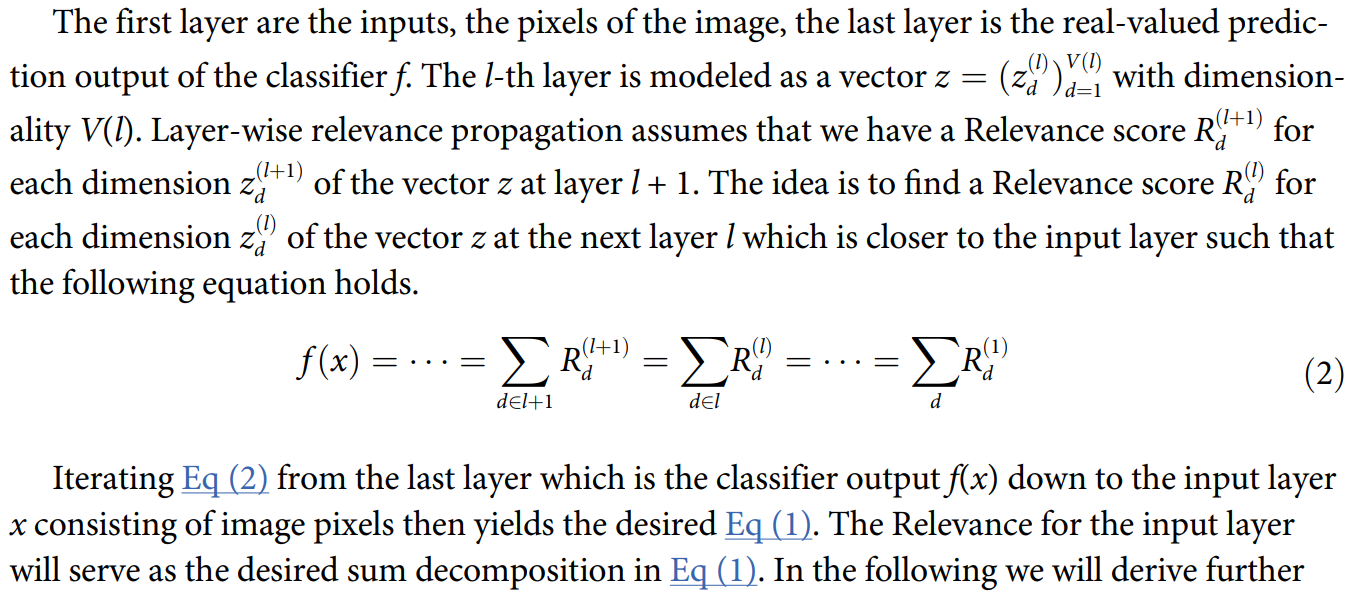
마지막 layer에서부터 input layer까지 쭉쭉 내려가면서 Relevance score를 계산한다. 그 과정에서 기여도의 총합은 같아야 한다는 것이다. 어떻게 보면 당연한데, 중간에 이미지가 바뀌지 않고 그냥 layer를 통과하면서 형식만 바뀌는 것이기 때문에 기여도의 총합이 달라질 리가 없다.

이렇게 그림으로 보면 더 쉽다. 마지막에 f(x)가 있고, 뒤에서부터 쭉쭉 내려가면서 R이 차례로 나온다. 약간 재귀함수 값들이 쭉쭉 구해지는 느낌이다. 그래서 input까지 간다. 결국, 식 자체로는 j번째 뉴런의 Relevance (기여도) 이지만, input image까지 가기 때문에 최종적으로는 f(x)에 대한 image pixel의 기여도까지 가는 것이다.
여기서 Relevance Conservation Constraint를 다시 보면,

이전 R들을 다 더한거랑 뒤의 R이랑 같다. 라고 적혀있는, 보존이 잘 되고 있는 모습을 볼 수 있다.
Relevance Score 계산하기

위의 그림을 다시 보자. 그림 상에서는 오른쪽에 R7부터 시작한다. 그리고 왼쪽으로 갈 수록 R7이 R47, R57, R67 이렇게 나눠진다. 이게 바로 Relevance Distribution이다.

중간에 있는 (5) 식을 보자.

R7에 뒤에 빨간색 동그라미 쳐진 term을 곱해주면 왼쪽으로 가면서 쭉쭉 relevance를 구할 수 있다. 당연히 i랑 j는 숫자가 달라지면서 여러 개의 R이 나오는 것이다.
각 term들에 대한 설명은 다음과 같다.

분모가 0이 되지 않게 stabilizer term인 epsilon이 하나 들어갔다.
Results and Experiments
다음은 저자들이 생성한 HeatMap으로, MNIST dataset에서 3과 8을 구분하는 실험을 진행하였다.
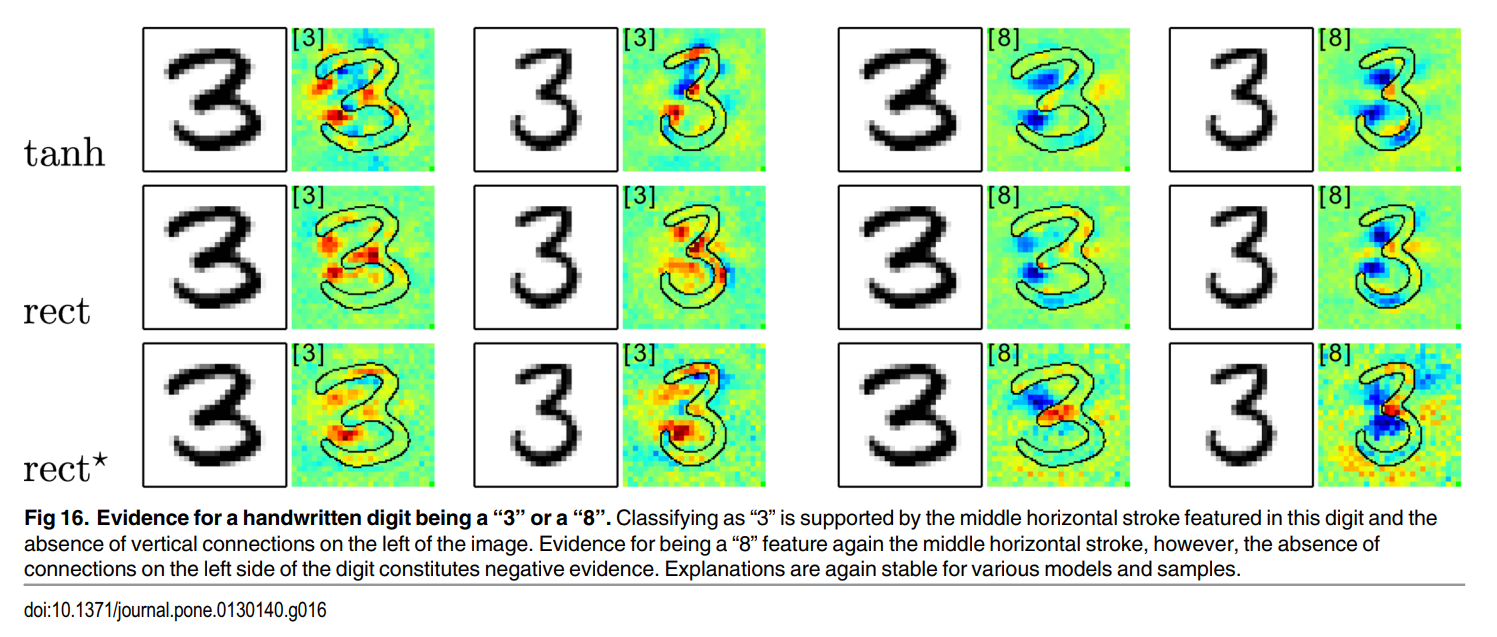
3과 8을 구분하는 HeatMap을 보면, 왼쪽 부분에 빨갛고 파란점들이 집중되어 있는 것을 볼 수 있는데, 이는 모델이 3과 8의 "왼쪽 부분이 연결되지 않은 차이점" 을 잘 캐치하고 있다는 모습을 볼 수 있다.
직접 구현
다음은 LRP를 이전에 했던 ImageNet의 snake 예시로 다시 구현해 본 것과, MNIST 로 다시 돌려본 것이다.

모델의 분류는 king snake로 사진을 분류하였고, 분류 점수는 약 22점 정도였다. 찾아보니 relevance score를 구할 때 epsilon rule 말고도 다른 rule들도 많았다. 일단은 epsilon rule로 구현을 진행하였고, 희미하지만 HeatMap을 보면 뱀의 마디마디에 빨간 점들이 찍혀있는 것을 볼 수 있다.
모델이 복잡해지고 깊어짐에 따라 (VGG19, ImageNet) 논문 원문에만 충실한 구현에서는 HeatMap이 잘 작동하지 않을 수도 있다.
다음은 MNIST를 활용한 HeatMap이다.

약간 애매하긴 하나, 숫자들의 테두리에 점들이 많이 찍혀있는 모습을 볼 수 있다.
Full code: https://github.com/ShinyJay2/Explainable-AI/tree/main/LRP
Explainable-AI/LRP at main · ShinyJay2/Explainable-AI
Implementations of XAI. Contribute to ShinyJay2/Explainable-AI development by creating an account on GitHub.
github.com