LLM 관련 base knowledge recap의 의미로, 이 게시물을 작성한다. 다음의 글을 참조하면 좋을 것이다.
https://www.krupadave.com/articles/everything-about-transformers?x=v3
Everything About Transformers
A visual, intuitive deep dive into transformer architecture: history, design choices, and the why behind attention, masking, and positional encoding.
www.krupadave.com
History of Transformer
처음에 개발된 feed forward network는 no memory, no order of context였다. 이들은 fixed pattern을 눈치채는건 잘했지만, 시퀀스를 handle할 수가 없었다. 메모리가 없기에 이전 상태에 대한 정보를 가져오는 법을 모르기 때문이다.
그래서 그 다음으로 나온게 RNN이다. 다들 알겠지만 같은 weight로 hidden state 계속 업데이트 해주며 쌓이는 방식이다. 이전 timestep의 정보를 가져올 수 있게 되었지만, 여러 layer의 반복적인 통과로 인해 exploding / vanishing gradient 문제가 대두되게 되었다. 이 문제 때문에 long term 정보를 이용하는데에 어려움이 있었다.
이에 적절한 조작은 가한 LSTM, GRU 등 gating을 이용해 hidden state와 context의 정보량을 적절히 조절하는 방안들이 나오기 시작한다. gating을 통해 gradient가 잘 흐르도록 만들어줌으로써 더 과거의 정보까지 이용할 수 있게 하는 것이다. (본 블로그의 LSTM 게시물 참고)
이후 seq2seq가 나오면서 encoder-decoder 구조가 소개되고, encoder가 input을 받아서 '고정된' 길이의 벡터 output으로 내주면 decoder는 그걸 받아서 (Context vector) 단어 하나가 들어가면 다음 단어를 예측하는 식으로 한 스텝씩 처리되는 과정을 거친다. 전체 input을 fixed length vector로 내기 때문에 모든 context 정보를 다 집어넣기가 어려웠던 단점이 있다.
그리고 이제 transformer인데, attention을 이용해서 위치적 정보를 맥락에 넣어주고 long range dependency도 가능하게 해주었으며, 병렬 연산과 줄어든 traning time을 제공해준다. 문제는 attention 계산이 quadratic하게 expensive하다는 점과 효과적인 훈련을 위해서는 large dataset이 필요하다는 점이다.
결국 어느 순간, recurrence를 갖다 버리고 attention만 쓰자가 transformer의 탄생이다.
이전에는 이랬다면,

transformer는,

라고 보면 된다.
Transformer Architecture Breakdown
구조는 Encoder-Decoder 구조로 되어있다. 요즘 모델들은 decoder가 encoder의 역할(임베딩이라던지)을 잘 수행해낼 수 있다는 것이 밝혀져 decoder only 모델이 주를 이룬다(ChatGPT 등). 어쨌든, encoder-decoder 구조 내에 5가지의 테크닉:
1. Attention
2. FFN (feed forward net)
3. Layer Norm
4. Positional Encoding
5. Residual Connection
이 들어가 있다.
이거 말고 다른 그림을 직접 그린걸 수록해본다.

이걸 좀 더 확대해보면,

대충 위의 구조라고 생각하면 된다. encoder는 input을 받아서 numerical representation으로 바꿔주고, decoder는 이 representation을 받아서 one token at a time으로 결과를 생성한다.
Tokenization / Word Embedding
Attention mechanism으로 들어가기 전에 실제 문장이 어떻게 숫자로 바뀌는지부터 알아야 확실히 모델 구조와 실제 데이터 간의 간극을 메꾸면서 이해할 수 있다.

Transformers are cool이라는 문장을 각각 다른 type의 토크나이저로 분해한 결과물이다. 이처럼 문장/단어를 쪼개서 뭔가 각각의 토큰으로 만들어주는 것이다.
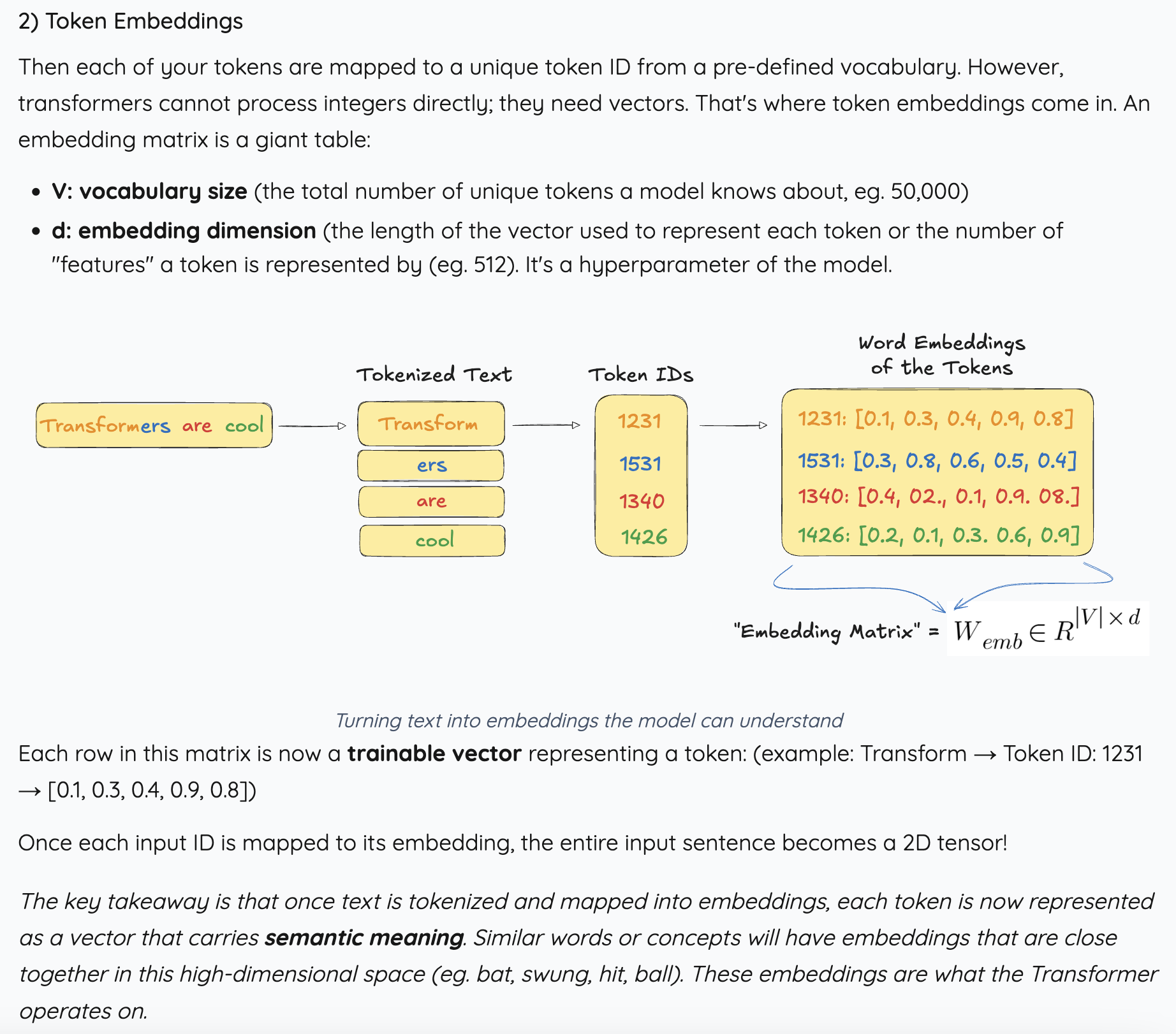
그 다음에 각각의 토큰들에 unique한 ID를 부여하고, 그 ID를 vector로 만들어주는 과정이 바로 word embedding이다. 여기서 가장 중요한 부분은 유사한 단어나 의미를 가진 vector들이 high-dim representation 공간 안에서 서로 가깝게 위치해 있을 것이라는 부분이다. 이 embedding을 가지고 Transformer는 노는 것이다.
Attention
우선 결과물부터 정리하자면, 우리는 단어의 의미와 context 정보를 모두 담고 있는 representation을 만들고 싶은 것이다.
이를 위해서는,
value vector x softmax(attention score) = 새로운 representation
이 되는 것이다. 이렇게 기억하는 것이 가장 직관적일 것이다. Attention하면 모두들 QKV를 떠올릴 텐데, Query와 Key를 이용해서 내용의 중요도를 판단하는 점수를 만들고 그걸 내용 (Value)에 곱해주면 그게 "새로운 정보를 담은 내용" 이 되는 것이다. 그냥 존재하는 내용에 정보를 더해준다 생각하면 된다.
매우 직관적인 예시가 아래와 같다.

Query는 그냥 우리가 원하는 질문이라고 생각하고, Key Value는 dictionary(Hashmap)의 그것이라고 생각해도 무방하다. 위의 구글 예시로 들면,
1. 웹사이트 제목(K)이랑 우리가 찾는 내용(Q)이랑 유사하다 싶으면 --- QK의 내적값이 높으면
2. 웹사이트 속 내용(V)에 높은 점수를 부여하고 싶다 --- QK의 내적에 V를 곱해준다.

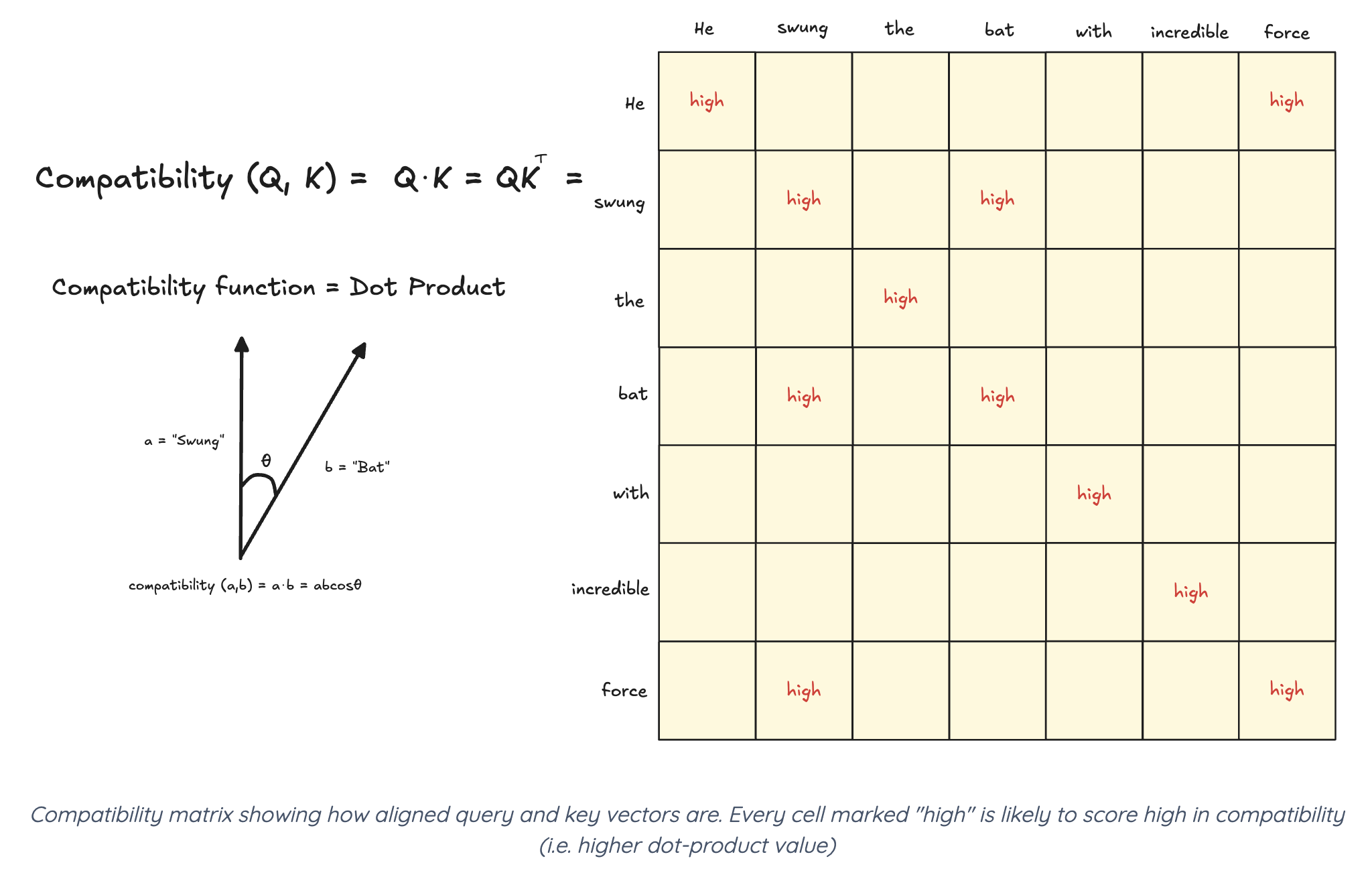
방금까지는 QK의 내적만 말했지만, 하나의 문제가 있다. 내적값이 크면 activation function에 걸릴 때 극단적인 값이 나올 것이기 때문에 vanishing gradient 문제가 생길 수 있다는 점이다. 그래서 후처리로 dimension 값으로 내적값을 나눠줄 것이다.
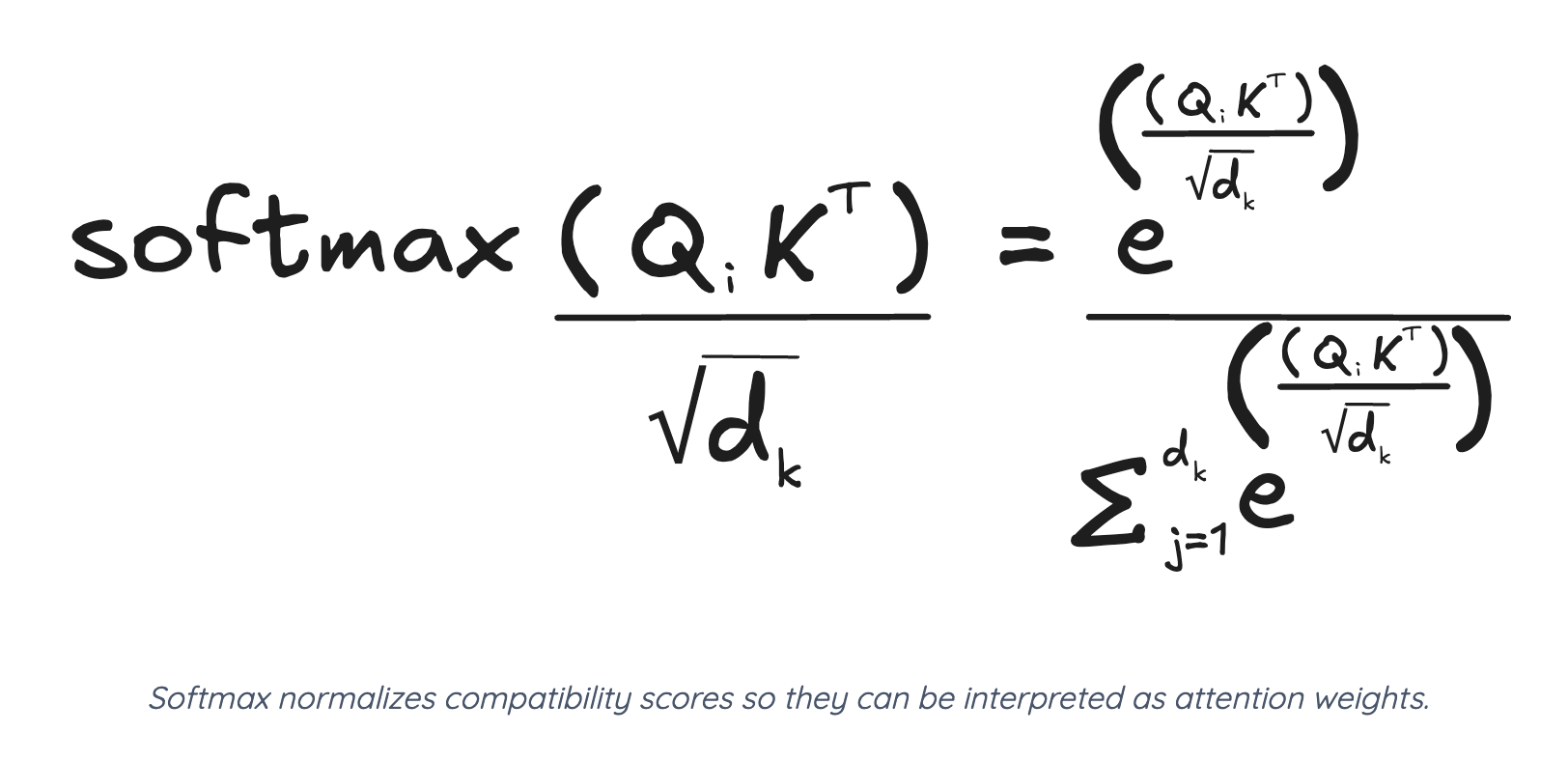
LSTM 게시물에서도 보면 알겠지만 인공지능에서 어떤 숫자를 0-1 사이의 점수로 normalize해줄 때 softmax를 주구장창 사용한다. 밑에 루트 d가 차원 수로 나눠준거다 (너무 커서).

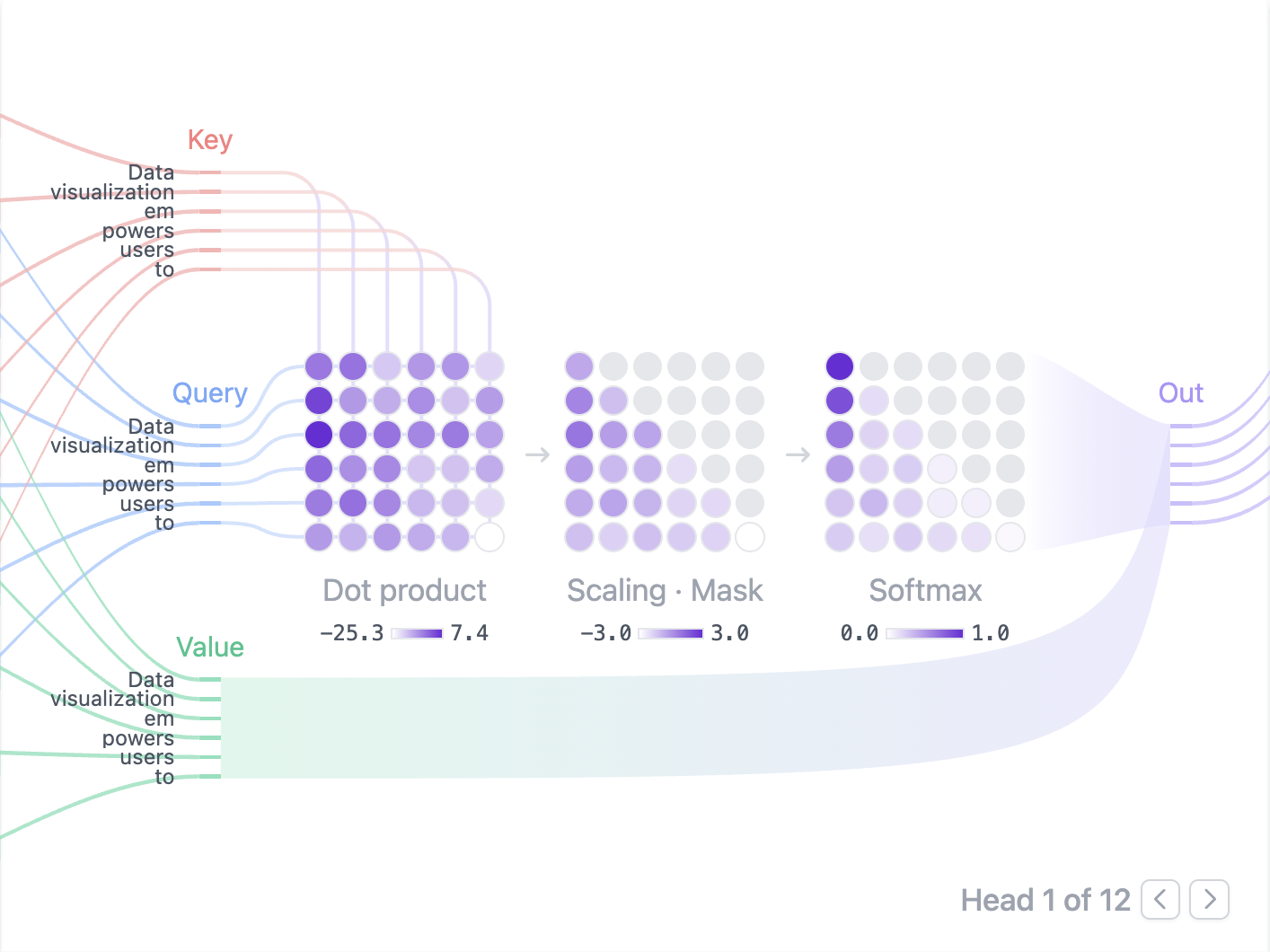
그러면 점수가 대충 이렇게 된다. 각 숫자들이 할당된 attention score가 되는 것이다. 이제 여기에 value matrix를 곱해준다. Value matrix는 input sequence의 각 토큰을 벡터로 만든 애들의 집합이다 (문장 내용이라 생각하면 편하다).
결국 이렇게 해서 우리가 아는 Attention이 나온다.
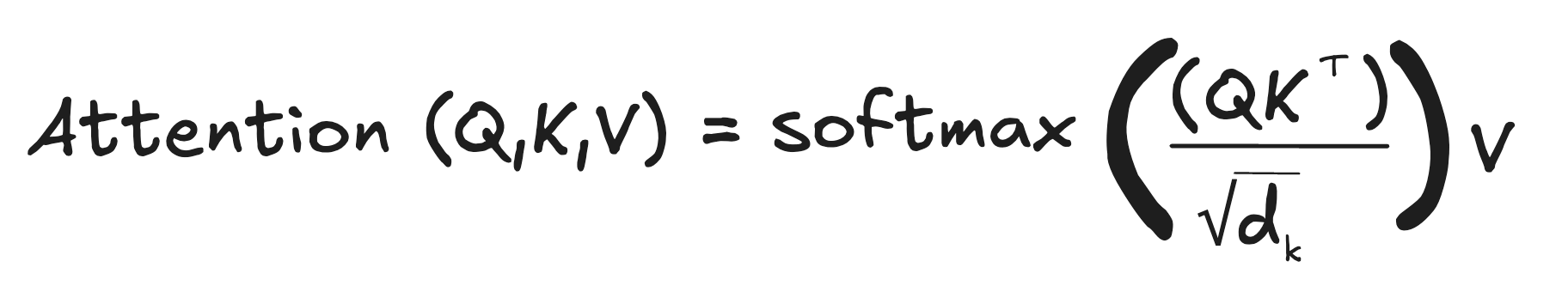
Multi head Attention
우리가 사회를 살아갈 때도, 한 문제에 대해 여러가지 관점을 가진 사람들이 있을 수 있다. 이들을 한데 모아서 문제 해결을 시킨다면 더 효과적인 문제 해결 방법이 나올 수도 있지 않을까? Multi head attention도 이런 느낌이다. 다음의 설명을 읽어보자.

하나의 attention이 내용을 보는 하나의 '관점' 이라고 생각하면 된다 (뭐가 중요한지 알아서 판단하여 점수를 매겻으니 그 내용에 점수를 매기는 하나의 방식 및 관점이라고 생각 가능). 그러면 여러 개의 '관점'을 돌려서 합치면 더 낫지 않을까?

Attention head를 몇 개로 할 지에 대한 논의가 있는데, 인공지능에서 어떤 값을 정할 때 모든 것에는 항상 trade off가 있기 마련이다.

너무 적으면 하나의 attention이 너무 많은 관점을 배워야하고, 내용을 이해하는데 필요한 관점보다 너무 많이 설정하면 하나의 attention이 쓸데없이 작은 (의미가 없는) 관점을 배우게 된다는 내용이다. 뭐든지 적당히 내용에 맞게 하는게 generalization과 performance에 좋을 것이다.
Masked Self Attention (Decoder)
Decoder 부분에는 encoder와 살짝 다른 attention이 들어간다. 바로 masking된 attention이다. 이걸 잘 이해하려면 decoder의 동작 방법을 잘 알아야 한다.
Transformer는 sentence pair로 훈련된다. Source 문장 - Target 문장 이렇게. Source sentence는 encoder로 들어가고, Target sentence는 decoder에 넣어주는 것이다. 결국 target sentence가 하나의 "답" 으로써 기능하고, 이 답을 잘 맞추기 위한 학습을 진행하는 것이다.
그런데 우리는 학습을 하는 것이기 때문에, 부정행위를 하면 안된다. 이전의 토큰들이 주어지면 바로 다음 나올 토큰을 잘 내는 방법을 배우는 것인데, 여기서 다음의 토큰 정보를 미리 보고 복붙해서 답을 내면 안된다는 뜻이다. 그러면 "문장을 잘 내는 방법"을 학습하는게 아니라 "잘 복붙하는 법"을 학습하게 된다. 이 이유로 masked self attention을 해주는 것이다.

-inf를 하는 이유는, softmax를 지나면 0이 되기 때문이다. 이렇게 정보를 막아놓은 상태에서 attention score를 계산하는 것이다. 이는 autoregressive한 property를 보존하기 위함도 있다.
이런 식이다.
Cross Attention (encoder - decoder attention)
이제 encoder에서 처리한 내용과 decoder에서 처리한 내용을 이어주는 다리가 하나 필요하다. 그 과정이 바로 cross attention이다. cross attention에서는, output의 특정 단어를 생성하는데에 있어서 input의 어떤 단어에 가장 attend할지, 관심을 가질 지를 보는 과정이다.
최근 GPT와 같은 모델들은 decoder only 모델들로, generation에 특화된 친구들이기 때문에, encoder는 물론 이 과정도 없긴 하다.
Decoder에 target sentence를 넣어줄 때 기본적으로 옆으로 한 칸 밀어놓은 문장을 넣는다. 이는 다음 단어를 예측하는 구조를 만들기 위함이다.


encoder에서 나온 결과물이 key와 value가 되고, decoder에서 나온 결과물이 query가 된다. 과정은 self attention과 동일하다.

그 다음 score 계산하고
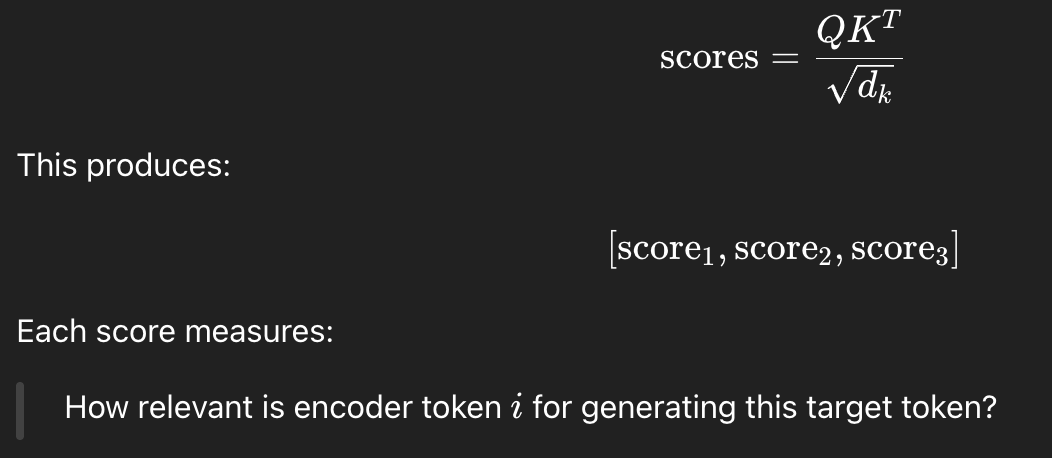
apply softmax

matmul 해주고

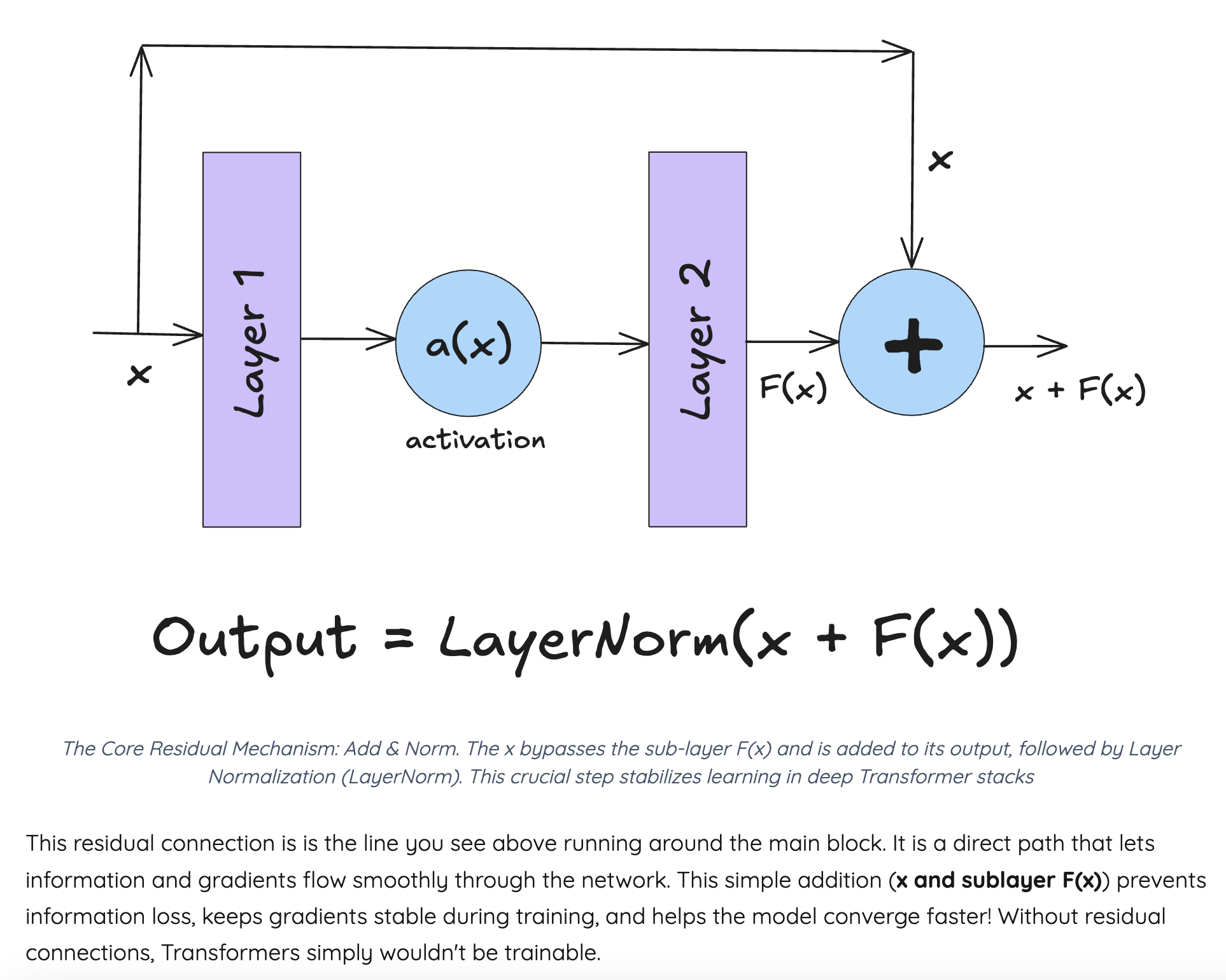
Add & Norm 해주면 된다.

FFN

FFN은 Attention에서 방향성을 잡아준 것을 가져다가 어떻게 하면 이 정보들을 풍부하게 해석할지를 위한 과정이다. non-linear transformations 을 더해주면, help the model detect deeper and more abstract features 하기 때문이다.



이외에도 residual connection과 positional encoding 부분이 있다. gradient가 더 잘 흐르게 해주는 skip connection 부분과, token의 위치정보를 넣어주는 positional encoding 부분이 있겠다.