
오늘은 MoCo에 대해서 다뤄볼 것이다. MoCo의 등장 배경은 이전 SimCLR에서 이어지는데, SimCLR의 한계점이 바로 large batchsize가 필요하다는 것이었다. 당연히 후속 연구들은 이러한 한계점을 개선하기 위한 노력을 하였고,
MoCo가 내놓은 해결책은 이전 batch의 representation들을 저장하는 것이다.
이것이 바로 MoCo의 "Momentum contrast"이다.
참고로 Facebook AI research의 논문이며, 저자들 중에 Kaimimg He가 있는데, ReLU를 쓸 때 사용하는 He initialization의 그 사람 맞다.
원문링크: https://arxiv.org/abs/1911.05722
Momentum Contrast for Unsupervised Visual Representation Learning
We present Momentum Contrast (MoCo) for unsupervised visual representation learning. From a perspective on contrastive learning as dictionary look-up, we build a dynamic dictionary with a queue and a moving-averaged encoder. This enables building a large a
arxiv.org
1. Introduction
일단 MoCo는 contrastive learning을 dictionary look-up task로 본다. 이게 무슨 뜻이냐면, 기존의 contrastive learning에서는 embedding space에서의 positive pair vector와는 거리를 minimize하고, negative pair와는 거리를 멀어지게 하는 방식이었다.
MoCo에서는 dictionary에서 positive pair를 잘 찾아내고, negative pair는 잘 구별하는 방식을 쓴다. 그래서 논문의 Method 부분 3.1을 보면, Contrastive learning as Dictionary look-up 이라는 제목이 있다. 여기서 물론 dictionary는 이미지가 encoder 통과한 후 나온 representation들을 모아놓은 것이다.

저자들의 서술을 보면 알 수 있는데, 어떤 query가 있고, 그거에 대한 positive key, 그리고 negative key들이 있으며, 그것들에 대한 InfoNCE(NT-Xent) loss를 사용함을 볼 수 있다. 그래서 1개의 positive key, 그리고 K개의 negative key로 구성된 K+1-way softmax loss를 사용하는 것이다.
query는 뭐고 key는 또 뭐고, 얘네들은 대체 어떻게 등장하는 것인지? 그래서 이미지 하나를 넣으면 모델이 어떻게 돌아가는지? 이런 의문이 들기 시작한다면 다음 MoCo의 동작 방식을 보도록 하자.
2. Method
일단 MoCo의 작동방식을 한 눈에 보여주는 figure를 띄워놓고 하나하나 보자.
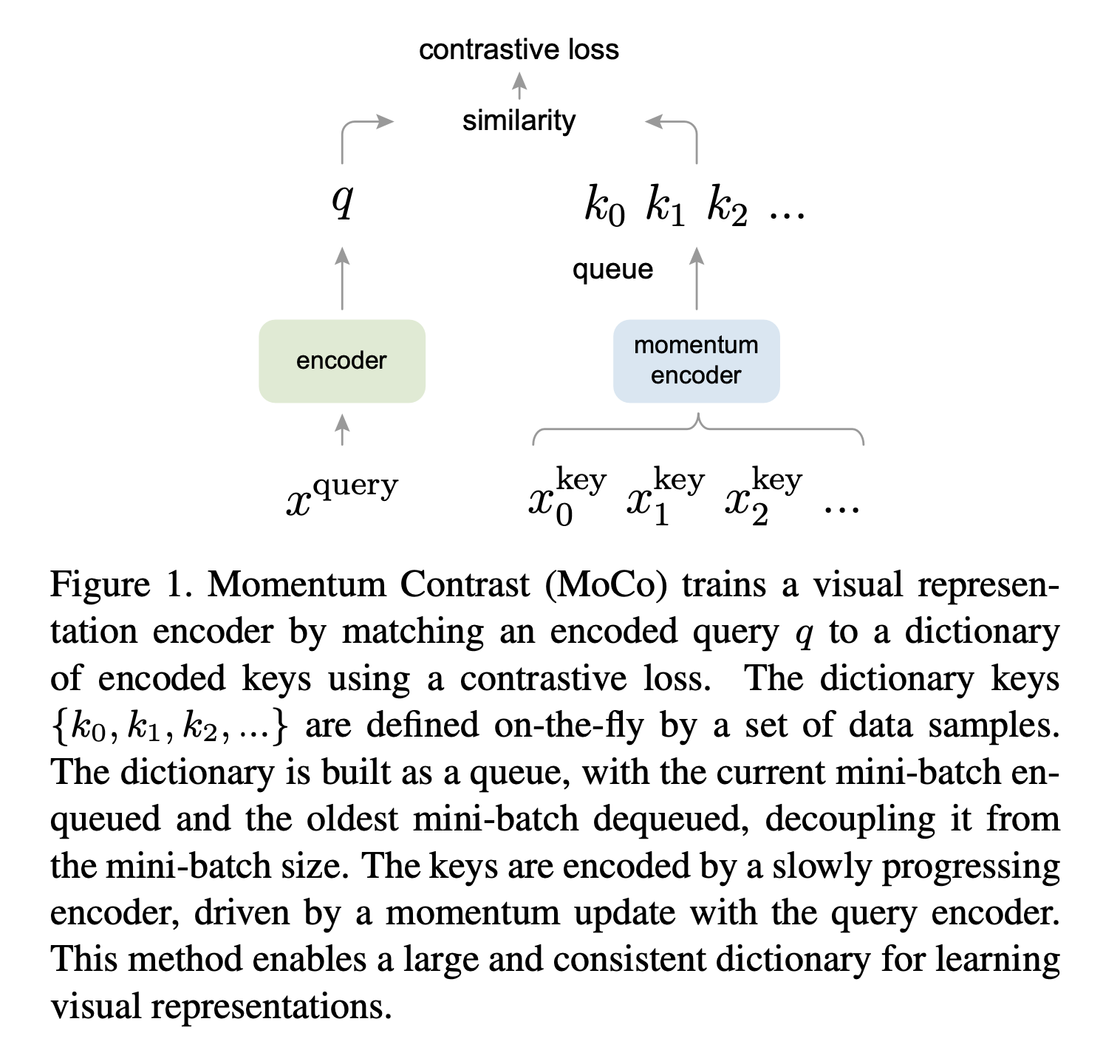
Dictionary as a Queue
일단 원본 이미지 x가 위의 그림처럼 x_query와 x_key로 바뀐다. 그리고 그림을 보면 k개의 key들이 있는데, 이건 이전 minibatch의 key들과 현재 minibatch의 key들이 섞여있는 queue 구조이다.

이것도 SimCLR과 마찬가지로 다른 parameter를 가진 transformation을 적용해서 x_q와 x_k를 각 이미지 당 만든다. 여기서 나온 x_q는 encoder로, x_k는 그림처럼 momentum encoder로 들어가는데, 이 k+ 가 우리 query의 유일한 positive example이 되는 것이다.

여기서 dictionary는 K+1 개의 요소들을 가지는데, positive example 1개, 그리고 나머지 K개의 negative example로 구성되어있다. K는 우리의 minibatch size보다 큰데, 이는 previous batch의 negative example들을 저장하기 위함이다. 이 글 맨 위의 볼드체로, SimCLR에서의 한계인 large batchsize를 극복하기 위해 이전 representation들을 저장한다고 되어있는데, 바로 이 부분이다.

이건 queue 형식으로 제일 오래된 N개의 key들을 빼주면서, K의 size를 계속 유지한다.
그래서 가지고 있는 K개의 negative example과 (분모에 K) 1개의 positive example을 이용하여 K+1 way softmax loss를 걸어버리는 것이다.

일단 여기까지 MoCo가 어떻게 이전 representation들을 저장하고 사용하는지 알아보았다. 하나 더 봐야할 부분이 있는데, 바로 그림의 momentum encoder 부분이다.
Momentum Update
그림을 다시 보자.

MoCo를 보면, encoder에만 gradient가 흐르고, momentum encoder에는 gradient가 흐르지 않는다. gradient가 흐르지 않는다는 뜻은 momentum encoder의 parameter는 gradient로 업데이트 되지 않는다는 뜻이다. 그럼 이 parameter는 어떻게 업데이트 될까?
해답은 "encoder 보다는 약간 느린 momentum encoder" 를 쓰는 것이다.

일단 우리가 여러 개의 key가 들어있는 queue를 쓰는 이유는, 과거의 representation을 활용하기 위해서이다. 그러면 동일하거나 비슷한 대상을 표현한 과거의 representation과 현재의 representation이 어느 정도는 비슷하게 유지되어야 한다. Many past step의 key들이 어느 정도의 consistency가 유지되어야 한다는 뜻이다.
직관적으로 이해해보자면, query의 encoder는 gradient를 받아서 "jump" 하면서 이리저리 업데이트 될 수 있지만, 여러 timestep에 걸친 key들을 담당하고 있는 momentum encoder 부분이 각 timestep 마다 이리저리 jumping 하면서 업데이트 될 경우 같거나 유사한 이미지를 아예 다른 식으로 representation을 뽑아낼 수 있기에 안된다는 것이다.
이걸 방지하기 위해 encoder와 비슷하지만 약간 과거 버전의 안정적인 타겟 네트워크가 되게끔 설정함으로써 representation이 막 바뀔 때는 쓰기 어려운 InfoNCE loss를 좀 더 효과적으로 쓸 수 있는 것이다.
저 위에 식이 어떻게 계산되는지는 여기를 보면 알 수 있다.

momentum encoder 부분도 [0.8, 0.1]이 되어버리면 안정적으로 있어야할 타겟이 막 움직이는 꼴이 되기 때문에 그걸 방지하고자 하는 것이다.
왜 이게 smoothly evolving embedding space를 유지하는지는, 아래의 그림을 보면 알 수가 있다.

query는 gradient를 받아 매 timestep마다 막 변화하는 반면, key embedding은 그것보다는 좀 더 작게, 덜 널뛰면서 변화하는 것을 볼 수 있다.
이렇게 설명 속에 파묻히다모면 본질과 직관적인 이해를 놓치기 쉬운데, 결국 여러 timestep에 걸친 key representation들을 가지고 있는 방법으로 large batch size가 필요하다는 단점을 상쇄시키려는 것이고, 이를 위해서는 여러 timestep에 걸친 key representation들이 어느 정도 일관성을 가져야하기 때문에, gradient를 받아서 업데이트 하는 것이 아닌, encoder의 업데이트를 따라가긴 하지만 천천히, 그리고 약간씩 따라감으로써 안정적으로 target (key들을 이용해서 negative고 뭐고 비교하는 것이므로) 이 되는 것이다.
사실 상 윗 문단이 momentum encoder의 전부이자 매우 직관적인 이해이다.
Results
이전 method들과 MoCo와 비교한 부분이 있고,

Momentum을 다르게 주면서 비교한 부분도 있다. 실제로 저렇게 업데이트 하는 것이 성능 면에서 좋다는 걸 보여준다.

Limitations
여전히 negative example들에 많이 구애받는다. 여러 negative들을 동일하게 밀어내기 때문에, 동일한 카테고리라도 다른 이미지에서 나온거면 negative로 취급하고 밀어내는 경향이 아직 있다. 그리고 여전히 다량의 negative example이 필요하다는 문제도 있다. 이에 따른 extra memory와 computational overhead도 존재하기 마련이다.
후속 연구인 BYOL이나 SimSiam에서는 아예 negative example 없이 연구를 진행하는 모습도 보인다.